I found the reaction of various internet personalities to the Wanger attempted mutiny in Russia entertaining. So many people letting their biases show – indulging in confirmation bias when they reacted to the news as it came in.
The guys at Defense Politics Asia were also amused. In this video, Defense Politics Asia presented some of the internet memes that amused them.
The video is good for a laugh.
In my list of YouTube channels reporting on the war in Ukraine, I found that Defense Politics Asia was one of the better sources for daily updates (see How is the war going? and Following the war in Ukraine – an update). It was second on my list. However, I still rate Military Summary as the best channel for updates. The guy is Belorussian, and his summaries often provide information like the number of battle groups in each area, which is lacking in other summaries. It is worth remembering that this war probably has more to do with the destruction of enemy forces than the capture of territory. He also does get into speculating on the likelihood of impending battles (interesting but not necessarily correct – the hardest thing to predict is the future). He comes across as knowledgeable but objective
These statements give me hope. I am so used to seeing people relying on a comfortable narrative without acknowledging evidence – reality. In fact, this seems to have become a habit for our mainstream media in recent years. This is why our media has gotten used to promoting misinformation and disinformation (and cynically accusing others of doing it) in place of news and political analyses.
But such reliance on comfortable narratives instead of evidence cannot last. Eventually, these lies get exposed and this can’t come soon enough for me.
Western politicians fooled by false beliefs
Western politicians fell into the trap of believing their own narratives, their own disinformation and propaganda when it came to Ukraine. History shows that it is simply a recipe for defeat.
Consider the economic war the US and NATO launched against the Russian Federation. They were so used to promoting false narratives like those of John McCain that “Russia is a gas station masquerading as a country.” That the country was very weak economically and that it could be brought to its knees by US/NATO sanctions.
But none of this has happened. On the whole, the economic and financial indicators for Russia are going well. The country has reacted well to sanctions and in most areas (automobiles are an example) the ordinary citizen is not affected.
The War in Ukraine
While it is always difficult to reveal reality during wartime (the first victim of war is truth) there is also now a growing realization in the West that what we have been told about the progress of the war in Ukraine has been largely false. Until now our political and our mainstream media have given us a diet of wishful thinking and rosy propaganda. Ukraine is winning. The Russian military faces huge losses. Russia is running out of missiles, planes and shells. And this next big Ukrainian offensive will lead to Rusia’s defeat. Although the specifics of that defeat are never provided.
The awful reality is now beginning to surface – aided in part by recent leaks from the US military. The real Ukrainian losses are huge. The Ukrainians are concerned about shortages of shells. They have lost most of their air defences. Having lost most of the original military hardware they now rely on weapons and hardware supplies from NATO countries – and the NATO stocks themselves are getting low.
There is now talk of a probable Ukrainian defeat and the need to get peace negotiations going to minimize losses.
Reality is beginning to surface – not with all commentators yet but more and more with time. But the truth hurts, and many will continue to hold on to the false hope that “their side” will continue to win.
War is a serious business and political leaders should never go into that business relying on wishful thinking or false beliefs. This business is so serious that leaders should look for objective facts and analysis. The lives of many, many people are at stake.
But the politicians in the US and other NATO countries have committed the cardinal sin of believing in their own propaganda. This will have consequences for them.
Here is an interesting video of a talk about disinformation given by Radio host and media personality Garland Nixon to the Center for Political Innovations “Summit Against Hypocrisy” in Washington, DC, on March 25th, 2023.
He presents a powerful definition of “disinformation” given the current political atmosphere.
The fact is that the words “disinformation” and “misinformation” used in the current political sphere don’t mean what we might intuitively believe them to mean.
Those with a scientific background might believe them to mean objectively incorrect information – that doesn’t correspond to reality. That is not based on evidence. But, in their common usage today, these words simply mean information which doesn’t agree with the current narrative. the narrative promoted by our mass media, our politicians and those who attempt to manage our thinking.
The distinction is important. Not only because it helps us be aware that the imposed narratives are often not based on reality or evidence. But also because the words are commonly used today in a way which promotes censorship. The clamping down on any views that do not concur with the “official” narrative.
Often the “official” narrative is in fact disinformation in that it does not correspond to reality. It is not supported by evidence. Or is even contradicted by evidence. Any objective look at the prevailing political narratives in most countries will show this to be the case.
So, in fact, these champions of censorship, of the need to force social media algorithms to downplay what they describe as “disinformation” (but may well be very factual) are simply playing with words. They themselves are promoting misinformation or disinformation and are using these words to prevent the truth from coming out.
This hypocrisy about disinformation being used to enforce “official” narratives operates through government policy, the mainstream media, social media, and the cancel pressure which makes people afraid to voice any doubts they have.
In New Zealand/Aotearoa, this pressure and self-censorship are familiar to us in many fields. Consider the gender/transgender wars, the science debate (the place of mātauranga Māori in school science curricula) and the current war in Ukraine, its causes, origins and what is happening on the ground.
But we are also part of an international geopolitical information and media war where the dishonest use of the terms “misinformation” and “disinformation” is common. Consider NATO Stratcom – the NATO Strategic Communications Centre – which continuously labels anything which challenges its own propaganda as “disinformation.”
The recent vote on the draft Security Council resolution seeking to establish an independent UN inquiry into the sabotage of the Russian-European-owned natural gas line, Nord Stream I and II, disappointed many observers. There is widespread disapproval of the current Swedish/Danish/German investigation because of its secrecy, refusal to share information with the Nord Stream owners and the fact that information is being shared with the USA which is widely considered responsible for this sabotage.
The headline for the UN report of the vote is rather misleading – see Security Council Rejects Draft Resolution Establishing Commission to Investigate Sabotage of Nord Stream Pipeline. In fact, the resolution was not rejected – it just failed to get the minimum 9 votes required for its consideration. It received the support of Brazil, China, and the Russian Federation. No country voted against it but the other nine members of the Security Council (Albania, the UK, Gabon, Ghana, Malta, Mozambique, the UAE, the US, France, Switzerland, Ecuador and Japan) abstained.
Despite the result, most speakers in the resulting supported the concept of transparency in the investigation, were concerned with the seriousness of the crime and wished to bring the perpetrators to justice. The speeches, in effect, supported the content of the draft resolution which, according to the UN report:
“would have requested the Secretary-General to establish an international, independent investigation commission to conduct a comprehensive, transparent and impartial international investigation of all aspects of the act of sabotage on the Nord Stream 1 and 2 gas pipelines — including identification of its perpetrators, sponsors, organizers and accomplices.”
Interestingly, Dmitry Polyanskiy, Deputy Permanent Representative of the Russian Federation to the United Nations, does not see the result as a complete failure. For example, he attributes the Danish authority’s invitation to the Nord Stream operator to investigate the object recently found close to a pipeline to the demand for transparency in speeches at the Security Council.
What are the next steps for Russia 🇷🇺 on Nord Stream investigation ?
🔸“We ll move forward with our national investigation we have a criminal case opened.”
But why did the draft resolution fail to win the necessary support?
USA pressures UN Security Council members.
Simply the USA can influence the non-permanent members of the council to follow their lead. In this case, the abstentions meant the USA and UK did not need to use their veto vote – which would have looked bad. The US was confident that they had got sufficient abstentions to block the resolution without using their veto vote.
Of course, I cannot provide evidence of the arm-twisting, blackmail or other forms of pressure used in this case but over the years the USA has taken advantage of the fact that the UN is sited on US territory to pressure members. Here I will just refer to a well-documented case where the USA attempted to engage allies in a secret campaign of blackmail and pressure on non-permanent members to get a Security Council vote supporting a US/UK invasion of Iraq in 2003.
This is portrayed in the film Official Secrets. There is a short video trailer below:
In 2003, Katharine Gun was a young specialist working for Britain’s Government Communications Headquarters. She exposed a highly confidential memo that revealed the United States’ collaboration with Britain in collecting sensitive information on United Nations Security Council members in order to pressure them into supporting the Iraq invasion. Gun leaked the memo to the press, setting off a chain of events that jeopardized her freedom and safety, but also opened the door to putting the entire legality of the Iraq invasion on trial.
The film “Official Secrets” premiered three years ago. This tells Katharine Gun’s incredible story – I have watched the film and found it very impressive.
At the time Democracy Now an independent, global YouTube weekday news hour spoke with Katharine Gun. It also spoke with The Observer newspaper journalists, Martin Bright and Ed Vulliamy who reported on Gun’s revelations. And it interviewed Gavin Hood, the director of “Official Secrets.”
The interviews below are in two parts. They are rather long but provide a broad verification of the facts reported in the film and give a fascinating insight into the work of journalism when dealing with sensitive security matters.
Part 1: This U.K. Whistleblower Almost Stopped the Iraq Invasion. A New Film Tells Her Story
Part 2: 15 Years Later: How U.K. Whistleblower Katharine Gun Risked Everything to Leak Damning Iraq War Memo
The decision of the International Criminal Court (ICC) to issue war crimes arrest warrants for the Russian President and the Russia Children Ombudsman may have been welcomed by the ideologically committed but otherwise seems to have been greeted with widespread cynicism (see Situation in Ukraine: ICC judges issue arrest warrants against Vladimir Vladimirovich Putin and Maria Alekseyevna Lvova-Belova). The fact this announcement came on the 20th anniversary of the illegal US invasion of Iraq which led to an estimated million deaths of Iraqi civilians was not lost on most observers. More attentive observers also noted this was the 55th anniversary of the My Lai massacre where between 347 and 504 unarmed Vietnamese villagers were slaughtered by US soldiers. (SeeMỹ Lai massacre).
Bodies on a road leading from the village of My Lai in Vietnam in 1968. The unarmed civilians were shot dead by American soldiers. Photo: Ron Haeberle
So much for war crimes. The ICC simply does not have an objective or even-handed approach to such matters.
Unlawful “deportation” of children
But these warrants are meant to relate to “the war crime of unlawful deportation of population (children) and that of unlawful transfer of population (children) from occupied areas of Ukraine to the Russian Federation.” Mind you, the actual content of the ” warrants are secret in order to protect victims and witnesses.”
This sounds like another one of these secret documents which we are assured provides “likely” evidence of bad behaviour by the Russian Federation. We seem to have been swamped with those in recent years.
The trouble is that it is an easy charge to make (especially if we ignore the need for evidence) because the need to evacuate people (including children) from war zones and to provide refuge to civilians caught up in wars is primary. It is simply disingenuous to make such accusations in these situations – even if inevitable mistakes are made.
Before the West makes such disingenuous assertions consider what happened towards the end of the US war in Vietnam. According to Wikipedia::
“Over 2,500 children were relocated without their consent and adopted out to families in the United States and its allies. The operation was controversial because there was question about whether the evacuation was in the children’s best interest, and because not all the children were orphans.” (See Operation Babylift).
“In the final weeks of the Vietnam War, Operation Babylift evacuated more than 3,300 South Vietnamese orphans and placed them with adoptive families in the U.S.”
During that war, some Vietnamese parents left their children in orphanages simply to get care, and these children were taken by the US. Over time many parents or relatives found their children and many problems were resolved through normal legal channels without making emotional charges of war crimes against the US president at the time.
President Gerald R. Ford carrying a Vietnamese baby from Clipper 1742, one of the Operation Babylift planes that transported approximately 325 South Vietnamese orphans from Saigon to the United States, at San Francisco International Airport. Photo: U.S. National Archives
In this current war in Ukraine, military action occurs in populated areas. The military forces on both sides have a responsibility to ensure the evacuation of non-combatants from these areas as it is a war crime to use civilians as a shield (this happened in Mariupol where the ultranationalist Azov military group prevented the evaluation of civilians).
This article is written in the anti-Russian tone we expect from the Guardian but at least describes the case of a father who was separated from his three children during the evacuation from Mariupol to a transit camp and the checking of the father’s documents. Eventually, the father was released, and he was able to find out what had happened to his children and travel to Moscow and recover them from an orphanage. He was helped to do this by the Russian children’s ombudsman office – managed by Maria Lvova-Belov the ICC has labelled a war criminal.
So. Belova is labelled a war criminal by the ICC, accused of illegally deporting and detaining children and yet she and her organization is obviously helping to reunite families that have been separated!
The Russian Federation has taken in more Ukrainian refugees than any other European country – and has been doing this since 2014 (see Where are Ukrainian refugees going? – an update). This should not be surprising as this war is basically taking place in the Donbass which is populated by ethnic Russians -many of whom have relatives in Russia. It is natural for them to take refuge in Russia.
“All orphans and children left without parental care lived for a long time in children’s homes and orphanages in the Donetsk People’s Republic. After the evacuation of these institutions from the DPR, they lived in temporary accommodation facilities in the Rostov and Kursk regions.”
A similar article also notes that even during this process anomalies have been found and efforts are being made to reunite families:
“In addition, the children’s ombudsman met with two mothers who had turned their children over to institutions. In both cases, the families were facing hardship. They were offered assistance in gathering documents to make them eligible for benefits, putting them on a waiting list for a flat, and finding employment. Both mothers showed readiness to take their children back from institutions soon” (see Maria Lvova-Belova brought orphans from the DPR to the Nizhny Novgorod Region for placement with foster families).
The ICC has discredited itself
Evacuation of children from war zones is simply basic humanitarianism. Separation of children from their families can be an inevitable result in some isolated cases. However, these anomalies can be resolved using normal legal mechanisms.
The ICC’s actions of labelling people involved in the care of these children as war criminals is mischief-making. It does not help the children. Nor does it help the resolution of this conflict in Ukraine.
The ICC actions simply further discredit an organization which has already shown itself to be biased.
A very informative video discussion: Are we getting the whole story about Ukraine? | Robert Wright & Ivan Katchanovski
Getting objective information on the situation in Ukraine and the cause of this current war is not easy. There is the current censorship and blatant mainstream media bias – which has been going on for years. And it takes work to actually uncover the real facts.
This video is long and well worth watching as it brings out the historical facts. Ivan Katchanovski has done a lot of work on the origins of ultranationalism in Ukraine and the crimes of the neo-Nazi Ukrainian collaborators during World War II
He has also made a very detailed study of the massacres that occurred during the anti-government Maidan demonstration in Kiev in February 2014. This shows that the sniper shooting of demonstrators and police came from the ultranationalist side – not the government side. A “false flag” aimed at getting western support for the coup which overthrew the democratically elected president.
As I said, getting the truth often takes a lot of work – especially in situations like today when there is so much disinformation promoted by governments and the media. But Ivan Katchanovski has the facts and Robert Wright draws out those facts during the interview.
A long video but well worth watching if you want to get the whole story about Ukraine.
I warned about the trap of virtue signaling in my article Virtue signaling over Ukraine. This video is still relevant – but have we moved on since then?
The Russian invasion of Ukraine in February 2022 was universally condemned at the time. Or was it? Certainly, the political atmosphere in countries like New Zealand/Aotearoa was clear. Anyone arguing the Russian case was shouted down. Media sources like RT were banned. Social media took it upon themselves to actively censor any pro-Russia arguments. And the New Zealand government enthusiastically introduced anti-Russian actions with justification based on bias rather than logic.
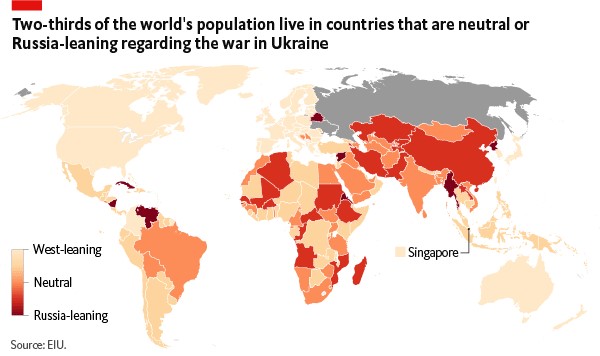
But even in those early days when 141 countries voted in favour of a UN resolution deploring Russia’s invasion of Ukraine, there were words of warning. The Economist Intelligence published this map in its article of March 30, 2022, “Russia can count on support from many developing countries”
This article pointed out that only “36% of the world’s population live in countries that have actively condemned Russia and imposed sanctions on its economy. Led by the US and the EU, this bloc includes all Western-leaning governments.”
However, “nearly one-third of the world’s population live in a country that has so far remained neutral.” Economist Intelligence warned, “that a significant share of these countries would align with Russia if tensions were to escalate.”
Added to this “another 32% of the world’s population live in a country where the government has supported Russia’s actions or where official declarations have echoed Russia’s narrative.” The article concluded that “these countries will try to benefit from closer ties with an anti-Western bloc, further reinforcing a split in the global economic and geopolitical landscape.”
Only a third of the world supported the US/EU/NATO condemnation of the Russian Federation. While another third was neutral, the fact is only a minority of the world was prepared to take any action.
The West vs the rest – it’s serious
These figures suggest that the world is now divided between a US-led minority and the “rest” a majority which refuses to go along with the US/EU/NATO narrative and actions.
In fact, this map shows that the US is taking economic actions (sanctions) against many countries in this majority.
Countries sanctioned in some form by the United States (as of 2022) according to Wikipedia. Map credit: JojotoRudess – Own work, CC BY-SA 4.0[/caption]
Sanctions are a form of economic warfare suggesting that this division of the world is serious and permanent.
The West now refuses to condemn Nazism and Racism
The rest of the world can be forgiven for coming to this conclusion. The map below shows the distribution of voting on the UN General Assembly resolution “Combating glorification of Nazism, neo-Nazism and other practices that contribute to fuelling contemporary forms of racism, racial discrimination, xenophobia and related intolerance.”
The final vote on this resolution last December was 120 in support, 50 against and 10 abstentions.
I am certainly very unhappy about our government’s vote on this resolution. Opposition to Nazism and racism should be accepted by all rational people. Our government should not have succumbed to pressure from the US/EU/NATO bloc on this resolution.
The majority of the world wants economic justice
Last December the UN General Assembly resolution “Towards a new international economic order“ was approved by 123 members, opposed by 5o (including New Zealand again) and there was 1 abstention.
The text of this resolution is very interesting. It calls for “a new international economic order based on the principles of equity, sovereign equality, interdependence, common interest, cooperation and solidarity among all States.”
It opposes “unilateral economic, financial or trade measures not in accordance with international law and the Charter of the United Nations that impede the full achievement of economic and social development, particularly in developing countries.” The majority of the world opposes the sanctions (really a form of economic warfare) imposed by the US/EU/NATO countries and their supporters like New Zealand/Aotearoa.
The resolution also demands “respect for each country’s policy space” and “respect the territorial integrity, national sovereignty and political independence of States.”
These are all things which I agree with, and it disgusts me that my country opposed these principles.
Conclusions
Let’s leave aside detailed arguments about the conflict between Ukraine and the Russian Federation – they can be discussed elsewhere. But I find the way counties have lined up on important issues like the need to oppose the glorification of Nazism and racism and important economic and financial principles related to justice and equality interesting. These are principles I willingly endorse, and I wish my country had sufficient independence to stand out against pressure from the US/EU/NATO and also endorse such important principles.
Sadly, our country does not have that independence. History will show we have chosen the wrong side.
Activists of various nationalist parties carry torches during a rally in Kyiv, Ukraine, Saturday, Jan. 1, 2022. The rally was organized to mark the birth anniversary of Stepan Bandera, founder of a rebel army that collaborated with Nazi Germany and murdered thousands of Jews, Poles, Russians and Ukrainians (AP Photo/Efrem Lukatsky)
I have not seen anything yet about rallies in Ukraine commemorating the birth anniversary of Nazi collaborator Stepan Bandera. These usually occur on January 1. Maybe such demonstrations in Kiev are banned under existing martial law. But this certainly has not stopped the commemoration of this birthday – after all Stepan Bander and other Nazi collaborators (responsible for the murder of thousands of Jews, Poles, Russians and Ukrainians in World War II are treated as national heroes in Ukraine.
For example, I hear from Eduard Dolinsky, Director General of the Ukrainian Jewish Committee that:
“The Verhovna Rada [Parliament] of Ukraine’s official FB and Twitter pages are celebrating the 114th birthday of Stepan Bandera.”
You cannot get a higher political level than that!
From the Twitter account of the Verkhovna Rada of Ukraine – Ukrainian Parliament (NOTE):
🇺🇦1 січня виповнюється 114 років від дня народження Степана Бандери (1909-1959).
Степан Бандера: 📌Коли між хлібом і свободою народ обирає хліб, він зрештою втрачає все, в тому числі і хліб. Якщо народ обирає свободу, він матиме хліб, вирощений ним самим і ніким не відібраний. pic.twitter.com/NxEmHa0SA7
“January 1 marks the 114th anniversary of the birth of Stepan Bandera (1909-1959).
Stepan Bandera: ‘When the people choose bread between bread and freedom, they ultimately lose everything, including bread. If the people choose freedom, they will have bread grown by themselves and not taken away by anyone.’“
And from the Facebook account of the Verkhovna Rada of Ukraine – Ukrainian Parliament (NOTE):
NOTE: Both the Twitter and Facebook posts of the Verkhovna Rada were highly criticized by mainly Polish commentators. Both posts have subsequently been removed. A similar post by the Verkhovna Rada last year listing current Ukrainian “heroes” including Bandera and other Nazi collaborators was removed after complaints by Polish commentators and politicians.
Eduard Dolinsky has also commented on several other events in Ukraine marking this birthday.
Yet people try to tell me that Ukraine does not have a neo-Nazi problem. That the ultranationalists in the National Battalions formed after the 2014 coup have all been weeded out. Etc., etc. The examples above are only a small fraction of the commemorations held for Nazi collaborators in Ukraine. Then there are all the street names, statues, etc., commemorating these murderers.
Don’t tell me Ukraine doesn’t have a neo-Nazi problem!
Of a possible 55 heads of state, only four made time to join a virtual address delivered by the African Union Assembly on June 20 by Ukrainian President Volodymyr Zelensky. Source:Ghana Web
So Ukrainian President Volodymyr Zelensky is to address the NZ Parliament next Wednesday. The address will be outside business hours (I will be interested to see how many MPs turn up) but it will please our Prime Minister, Jacinda Adern, who has pushed hard to get this address. As she sees it:
“This address is a valuable opportunity to reiterate our support for Ukraine directly to President Zelenskyy and hear from him what the international community can do to continue to support its people, and its sovereignty.”
But the New Zealand people don’t appear to share the Prime Minister’s enthusiasm for Zelensky. Just look at the negative comments this news received on the Twitter announcements of the address by the NZ Herald, News Hub Politics, and 1News NZ.
Ukrainian flags were everywhere 9 months ago. Twitter activists used them in their comments.
Gone are those Twitter activists from 9 months ago who proudly virtue-signalled their support for Ukraine and hatred for Russia. They seemed to be everywhere. Nowadays such enthusiastic supporters are few and far between. The mood is quite the opposite.
There is an occasional “Slava Ukraini!” But the vast majority of comments are hostile to this address. Comments raise issues of the corruption in Ukraine, Zelensky’s personal corruption, his attitude of entitlement and his insistent demands for money and weapons, and his support for neo-Nazis in Ukraine.
Ukraine’s president Volodymyr Zelenskyy is the FT’s person of the year 2022. The 44-year-old has earnt a place in history for his extraordinary display of leadership and fortitude https://t.co/Rxsl03pzS8pic.twitter.com/ibp52B4N66
This surprises me as I expected that New Zealanders had blindly accepted the government’s position on Ukraine. Even accepting New Zealand’s UN vote against a resolution condemning the glorification of Nazis and racism (see Is New Zealand covertly supporting the glorification of neo-Nazism?). Western Governments and media have competed in glorifying Zelensky as a brave and charismatic leader. The Financial Times even listed him as their Person of the Year.
Has the person on the street resisted all this pressure and come to their own mind about Zelensky?
I realise that Twitter commenters can be unrepresentative because they tend to congregate according to their biases. But these comments were on news media Twitter posts, so I expect them to be more representative. Maybe Elon Musk has somehow changed the composition of Twitter commenters, but I doubt it.
Have more and more ordinary New Zealanders resisted the media and government pressures to conform over Ukraine and the war in Ukraine? Are more and more New Zealanders now thinking for themselves.
I think the more politically conscious amongst us have learned things about Ukraine and the causes of the war that they weren’t conscious of 9 months ago. The enthusiastic, but unthinking, support from Ukraine has dissipated. We have become more aware of the real nature of Ukrainian society and its recent history. We have become conscious of the 2014 coup which overthrew a democratically elected government. We now know now about the widespread influence of ultranationalists and neo-Nazis in society and in the military national battalions (see The subtlety of neo-Nazi influence in Ukraine – ignored by our media).
Whatever the reason I welcome this trend. A society blindly led by the government and media as happened 9 months ago is dangerous.